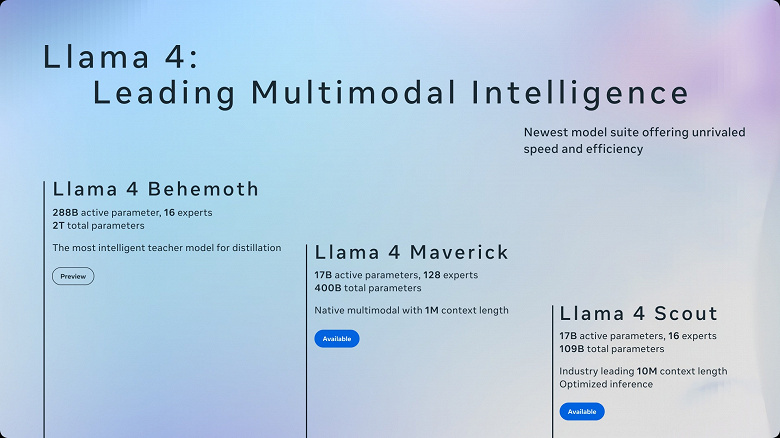
Meta* анонсировала новое поколение мультимодальных моделей Llama 4, способных обрабатывать текст, изображения и видео в беспрецедентных масштабах. Две ключевые модели — Llama 4 Scout и Maverick — уже доступны для разработчиков на платформах llama.com и Hugging Face, а в ближайшие дни появятся в сервисах Meta AI (WhatsApp, Messenger, Instagram*). Главное отличие от предшественников — раннее слияние модальностей: вместо раздельной обработки текста и изображений модель учится понимать их совместно, как человек, который изучает предмет через контекст.
Llama 4 Scout при компактных 17 млрд активных параметров (из 109 млрд общих) способна анализировать до 48 изображений за запрос и работает даже на одной видеокарте NVIDIA H100. Это делает её быстрее Google Gemma 3 с 27 млрд параметров, хотя версии для смартфонов пока нет. Контекстное окно Scout расширено до 10 млн токенов — эквивалент 20 часов видео или 5000 страниц текста. В тестах модель демонстрирует 100% точность в поиске информации в гигантских массивах данных и переводит редкие языки по методическим пособиям.



 5.39
5.39