
Итак, на данный момент спецификации ускорителя, который сама компания называет Nvidia H100 Tensor Core GPU, обновлены, и производительность повышена с 30 TFLOPS (FP64) и 60 TFLOPS (FP32) до 34 и 67 TFLOPS соответственно. Судя по всему, это достигнуто просто повышением частот с изначально заявленных 1775 МГц до примерно 1982 МГц, так как производительность в TFLOPS рассчитывается по простой формуле, где учитывается количество исполнительных блоков и частота.
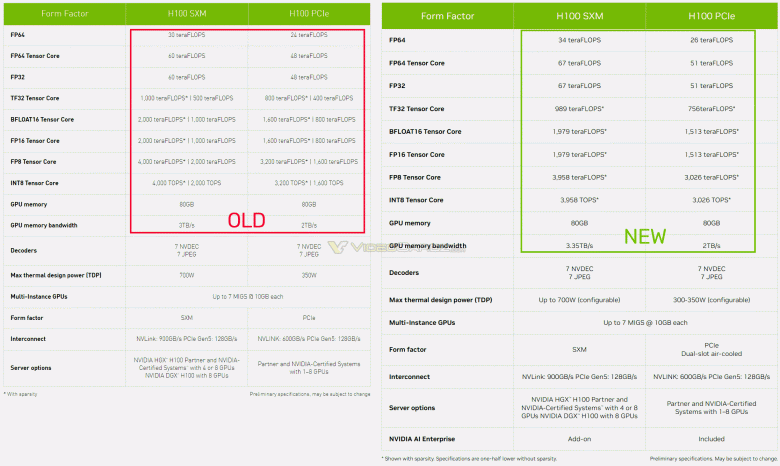
Стоит отметить, что указанная выше производительность справедлива для версии с интерфейсом SMX, тогда как модификация с PCIe менее производительна: 26 и 51 TFLOPS после обновления.
Также недавно появились указания на то, что будет доступна также версия со 120 ГБ памяти против 80 ГБ, которые указаны для всех версий сейчас.



 1.94
1.94